올해 3월, 트위터는 자신들의 추천 알고리즘 오픈 소스를 블로그와 깃을 통해 공개했다. 일단 블로그를 통해 공개된 전체적인 알고리즘을 리뷰하고 이후에 블로그의 여러 논문(Real Graph, SimClusters, ...)과 깃의 모델을 리뷰해보고자 한다.
트위터의 추천 알고리즘은 검색, 탐색, 광고 등 여러 부분에서 사용되지만 이번에 리뷰할 블로그에서는 For You 피드의 추천에 대해서 다룬다. 트위터에는 매일 5억 개의 트윗(트위터의 게시물)이 게시되고 이 중 몇 개만이 유저의 For You 타임라인에 게시된다. 그럼 어떻게 방대한 게시물 중 몇 개만을 샘플링하여 추천하는지 알아보자.
How do we choose Tweets?
트위처 추천의 기반은 Model과 Feature이다. Feature는 트윗, 유저, 반응에서 추출된 Latent Information(잠재적인 정보)이며, Model은 "서로 다른 유저가 미래에 상호작용할 확률이 어떻게 되나요?" 혹은 "트위터에 존재하는 집단은 무엇이 있으며 그 집단에서 유행하는 트윗은 무엇인가요?" 같은 중요한 질문에 답을 하도록 학습된 모델이다. 위와 같은 질문에 더 정확하게 답할수록 트위터는 유저와 더 연관된 트윗을 추천할 수 있을 것이다.
추천 파이프라인은 세 가지의 Main Stage로 이루어져 있다.
- Candidate Sourcing : 서로 다른 추천 소스에서 최적의 트윗을 가져온다.
- Rank : 머신 러닝 모델을 통해 각 트윗의 랭크를 매긴다.
- Heuristics and Filters : 유저가 차단하거나 선정적이거나 이미 본 트윗 등을 걸러낸다.
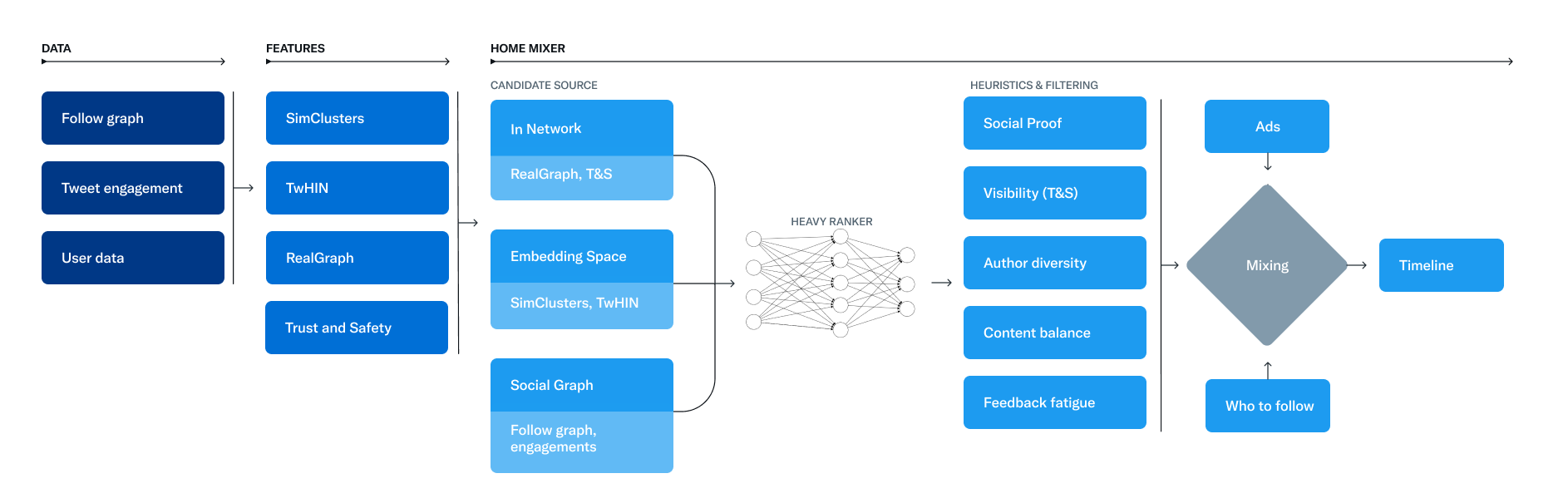
위 다이어그램은 For You 타임라인을 구성하기 위한 주요 컴포넌트들을 표시한 것이다. 다이어그램에서 Home Mixer는 For You 타임라인을 구성하고 제공하는 것을 담당한다. 이렇게 주요한 서비스를 담당하는 Home Mixer의 소프트웨어 Backbone인 Candidate Source, Ranking, Heuristics&Filtering, 그리고 Mixing&Serving에 대해 더 자세히 알아보자.
Candidate Sources: In-Network Source
트위터는 유저에게 새롭고 관련 있는 트윗을 가져오는 여러 Candidate Sources를 가지고 있다. 각각의 요청마다 소스에서 1억 개의 트윗 중 1500개의 트윗을 추출하며 해당 트윗은 당신이 팔로우하는 유저(In-Network)와 당신이 팔로우하지 않는 유저(Out-of-Network)를 통해 가져온다.
현재, For You 타임라인은 평균적으로 50%의 In-Network 트윗과 50%의 Out-of-Network 트윗으로 구성되어 있다.
In-Network Sources는 가장 큰 Candiate Source이며 유저가 팔로우하는 유저를 통해 가장 새롭고 연관된 트윗을 전달하는 것에 집중한다. 해당 트윗들은 팔로우를 통한 연관성을 기반으로 학습된 Logistic Regression 모델을 사용하여 효율적으로 랭크를 나누고 높은 랭크의 트윗들은 다음 단계로 넘어간다.
In-Network 트윗의 랭크를 매기는 것에서 가장 중요한 구성 요소는 바로 Real Graph이다. Real Graph는 두 유저의 Likelihood of Engagement(ex. 팔로우, 좋아요를 할 확률)를 예측하는 모델이며 특정 유저와의 Real Graph 점수가 높을수록 해당 유저의 트윗이 추천될 가능성이 높다.
Candidate Sources: Out-of-Network Sources
유저 네트워크 밖에서(유저가 팔로우하지 않는 범위에서) 유저와 관련 있는 트윗을 찾는 것은 까다로운 문제다. 트위터는 이 문제를 다루기 위해 두 가지 접근법을 사용했다.
Social Graph
첫 번째 접근법은 유저가 팔로우하는 유저의 Engagement(팔로우, 좋아요)나 비슷한 취향을 가지고 있는 유저를 분석하여 관련 있는 트윗을 찾아내는 것이다.
트위터는 다음과 같은 질문에 답을 하기 위해 Graph of Engagement를 탐색하였다.
- 최근 내가 팔로우한 유저들은 어떤 트윗에 반응(Engage with)했을까?
- 누가 나와 비슷한 트윗을 좋아하고 그들은 최근에 어떤 트윗을 좋아했을까?
위 질문의 답을 통해 몇 개의 트윗("최근 내가 팔로우한 유저들이 반응한 트윗"과 "나와 비슷한 트윗을 좋아하는 유저들이 반응한 트윗", 해당 트윗은 Out-of-Network)을 추출하고 Logistic Regression Model을 통해 랭크를 매겼다.
Graph 탐색은 위와 같은 Out-of-Network 추천에서 필수적이며 트위터는 유저와 트윗 그래프의 Interaction을 실시간으로 유지하기 위한 그래프 처리 엔진인 GraphJet을 개발했다.
Embedding Spaces
두 번째 접근법은 Embedding space 접근법이며 이는 "어떤 트윗과 유저가 내 흥미와 비슷할까?"라는 일반적인 질문에 답하는 것에 집중된 접근법이다.
Embedding은 유저의 흥미와 트윗의 내용을 통해 추출된 Nemerical Representations이며 두 유저끼리나 두 트윗끼리, 혹은 유저와 트윗끼리의 Embedding 유사도를 계산하여 연관성을 추정할 수 있다. 유저와 트잇의 Embedding을 더 정확히 추출할수록 Embedding 유사도를 관련 지표로써 사용할 수 있다.
트위터의 가장 유용한 Embedding Space 중 하나는 SimClusters이다. SimClusters는 Custom Matrix Factorization 알고리즘을 사용하여 특정 유저에게 파급력있는 유저로 구분된 커뮤니티(Cluster)를 찾아준다. 트위터에는 3주마다 업데이트되는 145k개의 커뮤니티가 존재하며 유저와 트윗은 포함되어 있는 커뮤니티로 나타낼 수 있다. 한 유저는 여러 커뮤니티에 소속될 수 있으며 한 유저가 특정 커뮤니티의 트윗을 좋아할수록 유저는 해당 커뮤니티와 더욱 연관되도록 한다.

Ranking
Candiate Sourcing을 통해 최대 1500개의 연관된 트윗이 추출되며, 해당 트윗들의 연관성 점수를 예측하고 예측된 점수의 등수로 랭크를 매긴다. 모든 트윗들은 어떤 Candidate Source에서 추출되었는지 관련 없이 동일하게 다뤄진다.
Ranking은 최대 4800만 개의 Parameter를 가진 Neural Network을 통해 이루어지며, 이는 좋아요나 리트윗 등이 Positive Engagement의 상호작용을 최적화하도록 학습된다.
해당 모델은 1000여 개의 Features를 입력받아 10차원의 Label을 결과로 출력한다. Label의 각 차원은 여러 Engagement의 확률에 대한 점수이며 해당 점수의 등수로 Rank를 매긴다.
Heuristics, Filters, and Product Features
Ranking 단계가 끝나면, 여러 Feature로 구성된 Heuristics&Filter 단계를 적용한다. 각 Feature를 통해 다양하고 균형잡힌 피드를 구성할 수 있도록 한다.
Feature는 다음과 같은 예제를 포함한다.
- Visibility Filtering : 유저의 선호에 따른 필터링 (차단한 유저의 트윗을 제거)
- Author Diversity : 한 저자와 연관된 너무 많은 트윗 제거
- Content Balance : In-Network와 Out-of-Network 트윗의 균형을 맞춤
- Feedback-based Fatigue : 유저가 Negative Feedback을 한 트윗에 대해서 감점
- Social Proof : Out-of-Network에서 2촌인 트윗만 사용 (내가 팔로우한 유저가 좋아요를 누른 트윗)
- Conversations : 답글 정보를 활용하여 더 큰 정보를 제공
- Edited Tweets : 해당 단계에서 편집된 트윗일 경우, 편집된 버전으로 교체하라는 알림을 보냄
Mixing and Serving
해당 시점에서는 Home Mixer가 추출된 트윗을 유저의 기기에 보낼 준비가 되었다. 마지막 단계로 추출된 트윗과 함께 광고, 팔로우 추천, 그리고 Onboarding 지침을 섞어 기기에 여러 게시물을 표시한다.
해당 파이프라인은 하루에 약 50억번 실행되며 평균적으로 1.5초 내에 완료된다.
해당 오픈 소스의 목표는 당신과 여러 유저들에게 트위터의 시스템을 완전 투명한(공개된) 상태로 제공하는 것이고 코드는 여기와 여기에서 확인할 수 있다.
'Paper' 카테고리의 다른 글
| [Brief Review] Are Neural Rankers still Outperformed by Gradient Boosted Decision Trees? (0) | 2023.04.24 |
|---|

댓글